Articles
Snowflake’s dynamic tables are a game-changer for continuous data delivery, offering an efficient method for transforming data within Snowflake. These versatile tables allow users to focus on the end-state and service level of their data pipeline while Snowflake handles infrastructure management and orchestration.
Read on to learn how this approach can streamline the data pipeline process, ensure reliable and consistent data transformation, and lead to faster and more actionable insights.
What are dynamic tables in Snowflake?
Dynamic tables are a fundamental element for continuous data pipelines, providing a simplified way to perform data transformations in Snowflake across both batch and streaming use cases. Essentially, dynamic tables refer to a type of table which takes a specified query as an input and automatically updates the results as the underlying data changes.
These tables support complex transformation logic and allow for the chaining of multiple tables. Dynamic tables are fully compatible with core SQL syntax, supporting joins, aggregations, unions, window functions, datetime functions, group by, filters, and more. They handle updates and deletes in source tables just as effectively as inserts, making them highly versatile for various data processing needs.
Additionally, you can activate streams on dynamic tables, making it possible to build event-driven architectures where downstream pipelines are triggered by changes in these tables.
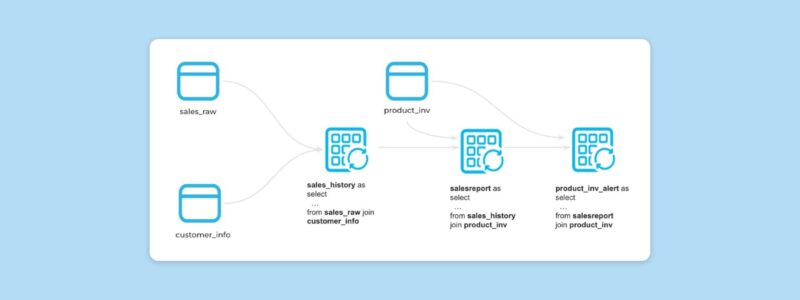
Moreover, dynamic tables support automatic incremental updates, which enhance both performance and cost management. With built-in support for snapshot isolation, they ensure the accuracy and reliability of your results by guaranteeing that all source systems are refreshed and synchronized to a consistent snapshot.
Using Snowflake’s dynamic tables
Snowflake’s dynamic tables automatically update and materialize query results, processing the latest changes to data as they occur. This makes them ideal for declarative data transformation pipelines, offering a dependable and automated approach to data transformation through simple SQL commands.
The following code snippet shows the core syntax for creating a Snowflake dynamic table: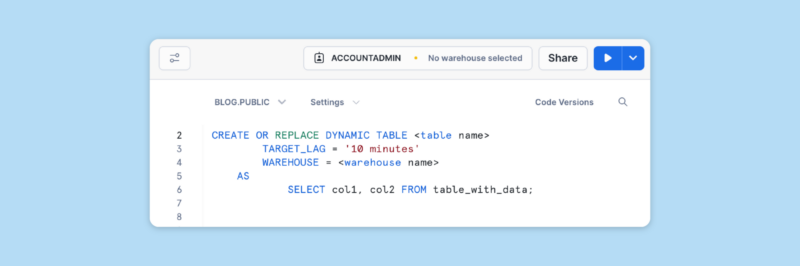
Using the specified Snowflake virtual warehouse, the resulting table will automatically refresh based on the SELECT statement and the target lag. According to Snowflake’s documentation, the target lag specifies the maximum amount of time that the resultant table’s content should lag behind the base tables included in the query. In the above example, the lag will be no more than ten minutes, ensuring that the data remains up-to-date within this service level.
How do dynamic tables compare with tasks and streams?
Traditional methods for transforming data in Snowflake, such as using streams and tasks, often require task configuration, managing dependencies, and scheduling, which can introduce additional complexity for some users. In contrast, Snowflake dynamic tables simplify this process by allowing you to define the desired outcome of the transformation, with Snowflake managing the pipeline for you.
Both dynamic tables and streams and tasks are essential tools for continuous data processing pipelines within Snowflake. While they serve similar purposes, there are distinct differences between the two approaches:
| Streams and tasks | Dynamic tables | |
| Approach | Tasks follow an imperative approach, where you write procedural code to transform data from base tables. | Dynamic tables use a declarative approach, where you write a query to specify the desired result, and data is retrieved and transformed from the base tables referenced in the query. |
| Scheduling | You define a schedule to execute the code that transforms the data. | An automated refresh process handles the schedule, ensuring the data meets the specified target freshness. |
| Code | Tasks can include non-deterministic code, stored procedures, UDFs, and external functions. | While the SELECT statement for a dynamic table can include joins, aggregations, window functions, and other SQL features, it cannot include calls to stored procedures, tasks, or external functions. This limitation arises because the automated process that refreshes the dynamic table must analyze the SELECT statement to determine the best refresh approach, which isn’t possible for all query types. |
Dynamic tables are particularly useful when:
- You do not require the granular control provided by using Snowflake streams and tasks for incremental and change data processing.
- You prefer to avoid writing code for managing data updates and dependencies.
- Your data freshness requirements are flexible and can be met with a target lag.
- You need to materialize query results from more than a single base table.
Overall, tasks can use streams to incrementally refresh data in target tables and can be scheduled to run regularly. Dynamic tables, on the other hand, automatically refresh based on the data’s target freshness, adjusting the schedule accordingly.
What’s the difference between dynamic tables and materialized views?
Dynamic tables in Snowflake allow customers to specify a query, with Snowflake materializing the results as part of the table’s output. This process is similar to materialized views, where data is written to storage, differing from standard views where results are calculated only when the view is queried or accessed.
While both materialized views and dynamic tables involve materializing query results, they serve distinct purposes:
- Materialized views are designed to seamlessly enhance query performance, while dynamic tables are intended for processing streaming data within a data pipeline.
- Materialized views rely on a single base table, while dynamic tables can be built from a complex query involving joins and unions.
- Data in materialized views is always up-to-date, whereas dynamic tables operate with a target lag time for data freshness.
Best practices to follow when using dynamic tables
Dynamic tables excel at streamlining and simplifying the data pipelining process, but it’s crucial to follow best practices to avoid costly mistakes and ensure optimal results.
Here are some key recommendations when working with dynamic tables:
- Optimize Your Queries: Optimize the query that defines a table to improve performance since it runs each time the table refreshes. Techniques like filtering, sorting and aggregation can help boost query efficiency.
- Properly configure and size the virtual warehouses used for dynamic tables: Ensure that the virtual warehouses associated with your dynamic pipelines are appropriately sized for your needs and have the correct auto-suspend settings for your use case.
- Monitor, Monitor, Monitor: Regularly check your dynamic tables to ensure they are refreshing properly. You can do this through the Snowflake API to monitor the status and performance of your tables.
- Leverage good security hygiene: Apply fine-grained security privileges to control who can access and modify your dynamic data pipelines. Role-based access policies and row or column masking on tables or their sources help maintain strict security and governance standards.
- Track Your Credit Consumption: Automated and serverless processes in Snowflake consume credits, so monitoring credit usage is essential to realizing the full benefit of continuous data delivery. Consider leveraging Snowflake’s tools in Snowsight to track warehouse usage and manage costs effectively.
Explore the potential of Snowflake dynamic tables
In summary, Snowflake dynamic tables offer a fully managed method for creating data pipelines, simplifying the process of data pipeline creation, including scheduling and orchestration. Leveraging declarative SQL syntax, they offer easy customization of data freshness settings, allowing you to fine-tune table latency according to your requirements.
Want to try out Snowflake’s dynamic tables today? Work through the Snowflake QuickStart here.
Don’t have a Snowflake account yet? Click here to try it out.