Articles
For most organizations today, “using AI” still means a single user types a single question into a single interface and hopes for the best. That approach was OK for exploration but is woefully inadequate for production work.
The biggest value in large language models is unlocked when AI is fully integrated into existing systems and workflows. Large language models ingest structured data, invoke other APIs and systems, are access controlled by roles and are themselves a part of a workflow. The biggest value is realized when the output of the AI is used as input to the next step in a process. This is AI orchestration, and there is a growing gap between organizations that are using Claude to simply search for answers and those that are using it as a programmable reasoning layer.
A poorly integrated AI system can leak data, make things up as it goes along (hallucinate), and create new shadow-IT risks that security teams can’t even keep track of. But a well-integrated system can save weeks of work for an analyst and do it in minutes or less, with a verifiable chain of custody for every token that is passed through the system.
This article is part one of a series that is intended to help technology leaders move past the proof-of-concept stage of evaluating large language models like Anthropic’s Claude to leveraging these models in production at scale. The article describes how to build out multi-step orchestration workflows that power down significant amounts of their technical resources work-per-minute while maintaining an auditable chain of custody for every token that passes through the pipeline. Along the way, it enshrines secure-by-design principles and warns off the most common pitfalls that bring production AI use cases to a screeching halt.
Why “Prompt-and-Pray” Fails at Scale
When AI interaction is limited to ad-hoc prompts, organizations will discover several predictable pitfalls.
- Context starvation: While individual prompts are typically starved for context, users can attempt to compensate for this by uploading sensitive information; such as internal documents, within the chat interface (a data-loss-prevention nightmare). This can result in a loss of intellectual property (IP) or significant reputational harm.
- Result fragility: The free-text result is not suitable for subsequent systems (such as CRM or workflow systems) without a fixed structure for processing the result. Each run can then easily lead to integration failures due to differing formats of the result.
- Auditability gaps: Although a prompt and answer are logged in the interface, there is no record of what data was sent, which model was used, or which guardrails were applied. These logs are typically not sufficient for a compliance team to conduct an audit.
- Duplicated work: Ten analysts work out a solution for the same problem by sending ten different versions of the same question to the chat. None of the answers is versioned or can be reused.
From Questions to Pipelines: The Five-Tier Orchestration Architecture
Orchestration reframes the interaction model. Instead of a human providing a prompt, the workflow engine constructs a prompt programmatically by pulling relevant context details from authoritative data sources, calls the API passing in the explicit details it has gathered, parses the response, and routes the results onto the next step which may be another API call, a database write, or a “human-in-the-loop” review process.
With orchestration, the mental model shifts from asking a question, to executing a particular reasoning step within a governed pipeline.
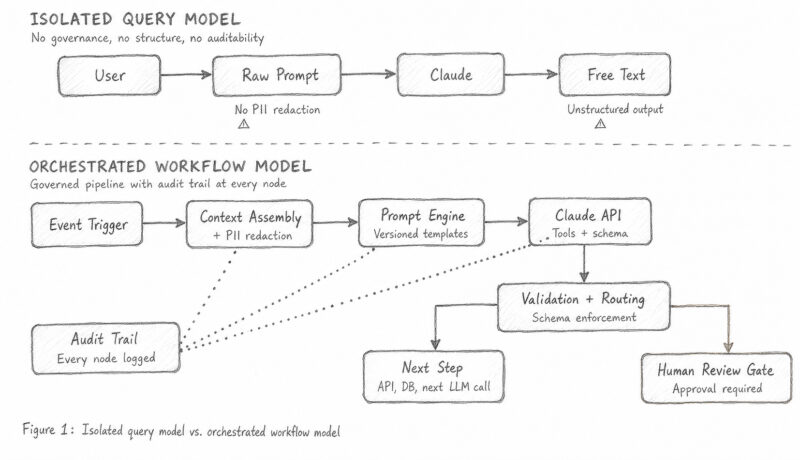
There is not a single system that enables production-grade AI orchestration, but five layers of abstraction that data goes through in a sequential manner.

The Ingress layer is typically comprised of an API Gateway that includes role-based access controls to allow only the correct users and systems to start the workflow. The Context Assembly layer then gathers all of the relevant data from various internal data sources while removing sensitive information such as PII before it is passed on to AI models. The Prompt Engine dynamically generates the appropriate parameterized prompt based on any required context and user inputs while treating prompts as deployable code artifacts similar to SQL or any other programming languages. This approach enables repeatable, governed, and auditable interactions with model interaction layer. The Model Interaction layer then makes the actual API call to Claude which handles aspects such as retry logic, token budgets, and streaming of the API response. The final layer, the Egress & Routing layer, validates the output of the AI model against a predefined schema, and then routes the results to the correct systems, or to a human for review when confidence is low.
This architecture is inherently secure by design, as opposed to being an afterthought, which means security strengthens as the amount of AI used in the organization increases, as opposed to decreasing.
An orchestrated AI workflow is secure by design because sensitive data never touches the AI model in raw form — it passes through mandatory redaction and validation gates before and after every interaction. Unlike isolated queries where users paste confidential documents directly into a chat window, the orchestrated model enforces a controlled pipeline: only authorized systems can trigger it, every input is sanitized, every output is validated against a schema, and every step produces an immutable audit record. The architecture follows the same zero-trust principles your organization already applies to production infrastructure — least-privilege access, network isolation, and no implicit trust in any single component’s output. The security isn’t a policy people must remember to follow; it’s embedded in the pipeline itself, making it structurally impossible to skip.
In short, this is what we mean by Secure-by-Design as security is not a bolt-on; it’s a design constraint that shapes every layer.
- Least-privilege API key management. Each workflow should use a dedicated Anthropic API key scoped to the minimum required model and feature set. Store keys in a secrets manager (AWS Secrets Manager, HashiCorp Vault, GCP Secret Manager) and never in environment variables baked into container images.
- PII redaction before model interaction. Run all user-supplied and database-sourced inputs through a redaction pipeline before they enter the prompt. Tools like Microsoft Presidio or custom regex-plus-NER pipelines can mask Social Security numbers, credit card numbers, and other regulated data. The model never sees what it does not need.
- Output validation. Never trust model output implicitly. Define a JSON schema for every structured response and validate against it before routing downstream. Malformed responses trigger a retry with an adjusted prompt, not a silent failure.
- Network isolation. The orchestration layer should run in a private subnet. Outbound traffic to api.anthropic.com should traverse a NAT gateway or egress proxy with allowlist rules. No lateral movement to production databases without explicit firewall rules.
From Blueprint to Build: Implementing AI Orchestration with Claude
In Part 1 of this series, we made the case for moving beyond the “prompt-and-pray” approach to AI. We highlighted four reasons why ad-hoc, single-shot prompting breaks down at scale: context starvation, result fragility, auditability gaps, and duplicated work across teams. We argued that the real value of large language models like Claude is not when they are used as a glorified search box, but when they’re embedded as a programmable reasoning layer within governed workflows.
We introduced the concept of AI orchestration: instead of a human typing a question, a workflow engine programmatically assembles context from authoritative sources, calls the model with structured inputs, validates the output, and routes results to downstream systems or human reviewers. To make this concrete, we presented a five-tier reference architecture (Ingress, Context Assembly, Prompt Engine, Model Interaction, and Egress & Routing) that gives organizations a blueprint for building production-grade pipelines with security, auditability, and repeatability built into every layer. We closed with the secure-by-design principles that should shape every orchestration deployment: least-privilege API key management, PII redaction before any data reaches the model, strict output validation against predefined schemas, and network isolation to prevent unauthorized access. The main idea here is that in an orchestrated system, security is not something for people to remember to do after-the-fact, it’s designed into your pipeline from the outset.
In Part 2 we move from architecture to implementation, starting with how to implement tool-use and function-calling with Claude. After that, we will discuss how to support multi-step chains and agentic patterns, as well as idempotency, context windowing, and circuit breakers. The bulk of Part 2 is dedicated to 5 battle-tested practices for implementing work-flows: treating prompts as version-controlled code, enforcing structured output contracts using JSON schemas, layering defenses against prompt injection, building in full observability to every step of your orchestration from day 1, and designing human-in-the-loop escalation paths for when things inevitably go wrong. Finally, we will outline a set of next steps for bringing your first workflow from blueprint to production.
Cheers and see you then.